Basis of spike sorting¶
In this section, we will review the basis of spike sorting, and the key operations that are performed by a human operator, in order to review and assess the quality of the data. The goal here is not to cover all the operations that one need to do when doing spike sorting, but rather to show you how key operations can be performed within the MATLAB GUI. If you want to have a similar description of those steps with phy, please see the phy documentation.
Note
All operations are similar across GUIs, so the key concepts here can be transposed to python/phy GUIs.
Viewing a single template¶
The algorithm outputs different templates. Each corresponds to the average waveform that a putative cell evokes on the electrodes. The index of the template displayed is on the top right corner. The index can be changed by typing a number on the box or clicking on the plus / minus buttons below it.

A view of the templates
The large panel A shows the template on every electrode. You can click on the Zoom in and Zoom out buttons to get a closer look or step back. To adjust the view, you can change the scaling factor for the X and Y axis by changing the values in the X scale and Y scale boxes just next to the template view. Reset will restore the view to the default view. Normalize will automatically adapt the scale to see the most of your template.
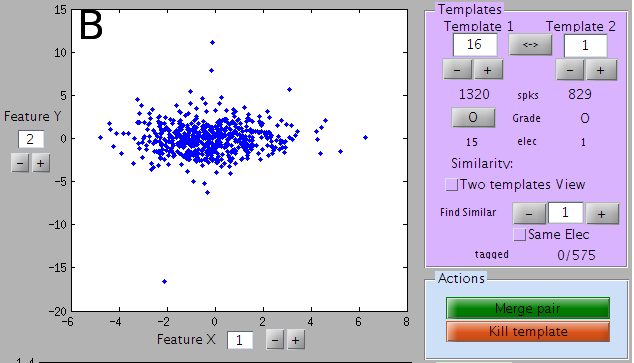
A view of the features
Panel B shows the cluster from which this template has been extracted. Unless you want to redefine the cluster, you don’t have to worry about them. You just need to check that the clustering did effectively split clusters. If you see here what you think are two clusters that should have been split, then maybe the parameters of the clustering need to be adjusted (see documentation on parameters)
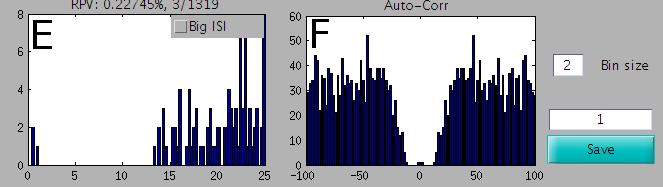
A view of the Inter-Spike Intervals and the AutoCorrelation
Panel E shows the ISI (inter spike interval). You can look at it from 0 to 25 ms, or from 0 to 200 ms if the button Big ISI is clicked. Above this panel, the % of refractory period violation is indicated, and a ratio indicates the number of violations / the total number of spikes. Panel F shows the auto-correlation, and you can freely change the time bin.
Note
If you are viewing two templates (see below), then Panel E shows combined ISI for the two templates, and Panel F shows the Cross-Correlogram between the two templates
Cleaning a template¶
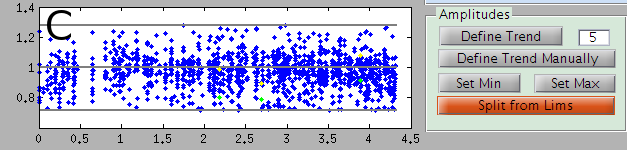
A view of the amplitudes over time
The template is matched all over the data, with a different amplitude each time. Each point of panel C represents a match, the y-axis is the amplitude, and x-axis the time. When there is a refractory period violation (two spikes too close), the bigger spike appears as a yellow point, and the smaller one in green. The 3 grey lines correspond to the average amplitude, the minimal amplitude and the maximal one.
Many templates should have a large number of amplitudes around 1, as a sanity check that the template matching algorithm is working. However, sometimes, some others can have amplitude that may be anormally small or large. These latter points are usually “wrong matches”: they don’t correspond to real occurrences of the template. Rather, the algorithm just fitted noise here, or the residual that remains after subtracting templates. Of course, you don’t want to consider them as real spikes. So these amplitudes need to be separated from the other ones and removed.
Note
The minimal amplitude is now automatically handled during the fitting procedure, so there should be no need for adjusting the lower amplitude
For this purpose, you need to define the limits of the area of good spikes. To define the minimal amplitude, click on the button Set Min, and then click on the panel D. The gray line corresponding to the minimal amplitude will be adjusted to pass by the point on which you click. The process holds for Set Max.
In some cases, for long recordings where you have a drift, you would like to have an amplitude threshold varying over time. To do so, you need to define first an average amplitude over time. Click on Define Trend and see if the grey line follows the average amplitude over time. If not, you can try to modify the number right next to the button: if its value is 10, the whole duration will be divided in 10 intervals, and the median amplitude will be over each of these intervals. Alternatively, you can define this average over time manually by clicking on the Define Trend Manually button, then click on all the places by which this trend should pass in panel D, and then press enter.
Once you have set the amplitude min and max correctly, you can split your template in two by clicking on the Split from Lims button. The template will be duplicated. One template will only keep the points inside these limits, the other ones will keep the points outside.
Viewing two templates¶
All these panels can also be used to compare two templates. For this, define the second template in the Template 2 box (top right), and click on the button View 2. This button switches between viewing a single template or viewing two at the same time, in blue and red. In E, you will get the ISI of the merged spike trains, and in F the cross-correlogram between the two cells.
Suggestion of matches¶
At any time, you can ask the GUI to suggest you the closest template to the one you are currently looking at, by clicking on Suggest Similar. By default, the GUI will select the best match among all templates. If the box Same Elec is ticked, then the GUI will give you only the best matches on that electrode. You should then be able to see, in the feature space (Panel B), the two distinct clusters. Otherwise, because templates are from point gathered on different electrodes, this comparison does not make sense. If you want to see the N - th best match, just enter N in the input box next to the Suggest Similar Button.
Merging two templates¶
Very often a single cell is split by the algorithm into different templates. These templates thus need to be merged. When you are looking at one cell, click on the Suggest similar button to compare it to templates of similar shape. If the number next to this button, you will compare it to the most similar one, if it is 2, to the second most similar one, and so on. You will be automatically switched to the View 2 mode (see above). In the middle left, a number between 0 and 1 indicates a coefficient of similarity between the two templates (1=perfect similarity). By ticking the Normalize box, the two templates will be normalized to the same maximum.
There are many ways to decide if two templates should be merged or not, but most frequently people look at the cross-correlogram: if this is the same cell, there should be a clear dip in the middle of the cross-correlogram, indicating that two spikes of the two templates cannot be emitted to too close to each other, and thus respecting the refractory period.
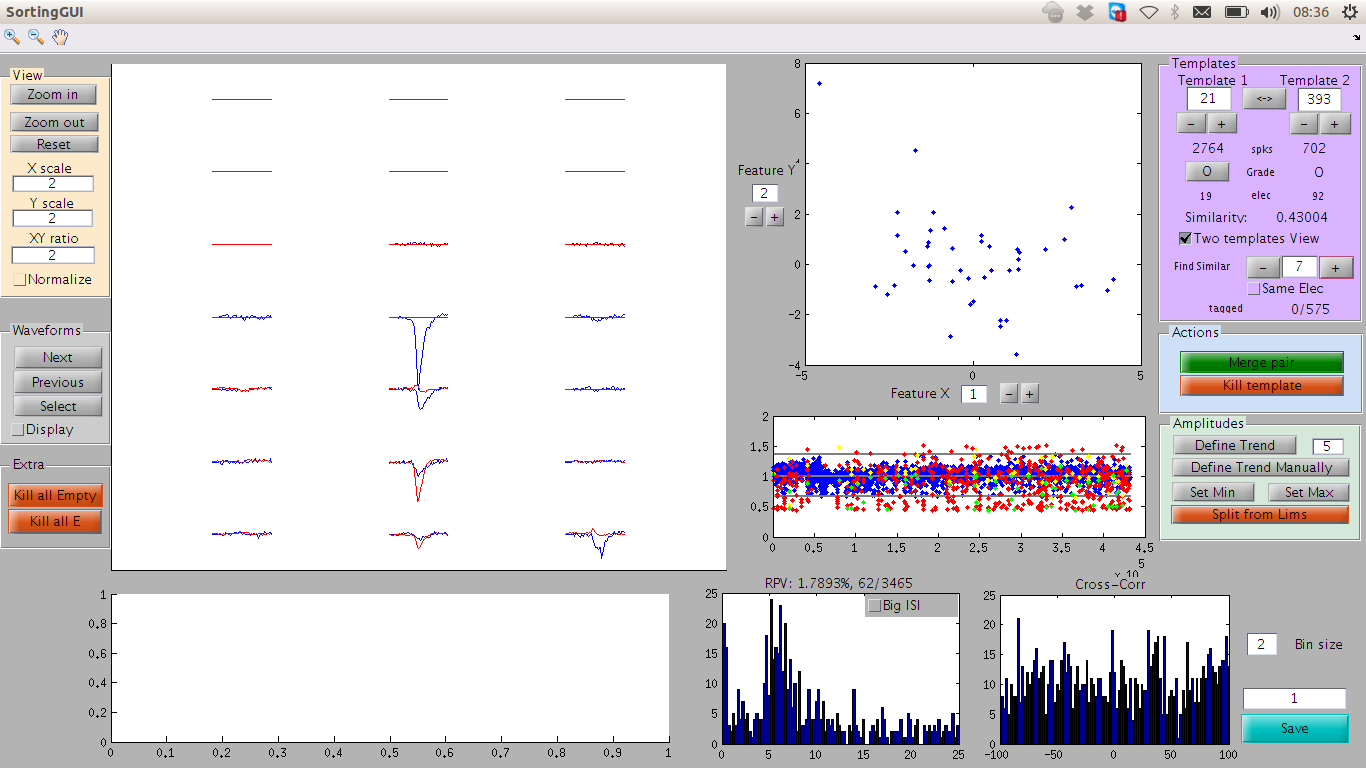
A view of the MATLAB GUI
To merge the two templates together, click on the Merge button. The spikes from the two cells will be merged, and only the template of the first one will be kept.
Note that the algorithm is rather on the side of over-dividing the cells into more templates, rather than the opposite, because it is much easier to merge cells than to cluster them further. So you will probably need to do that many times.
Note
Have a look to the Meta Merging GUI, made to perform all obvious merges in your recordings more quickly (see Automatic Merging)
Destroying a template¶
At any time, if you want to throw away a templates, because too noisy, you just need to click on the Button Kill. The templates will be destroyed
Repeats in the stimulation¶
- To display a raster, you need a file containing the beginning and end time of each repeat for each type of stimulus. This file should be a MATLAB file containing two variables, that should be MATLAB cell arrays:
rep_begin_time{i}(j)should contain the start time of the j-th repeat for the i-th type of stimulus.rep_end_time{i}(j)should contain the end time of the j-th repeat for the i-th type of stimulus.
The times should be specified in sample numbers. These two variables should be stored as a mat file in a file called path/mydata/mydata.stim, and placed in the same directory than the output files of the algorithm. If available, it will be loaded by the GUI and help you to visualize trial-to-trial responses of a given template.
Give a grade to a cell¶
Once you have merged a cell and are happy about it, you can give it a grade by clicking on the O button. Clicking several times on it will go through different letters from A to E. This extra information can be helpful depending on the analysis you want to perform with your data.
Saving your results¶
To save the results of your post-processing, click on the Save button. A number of files will be saved, with the suffix written in the box right next to the save button. To reload a given spike sorting session, just enter this suffix after the file name when using the circus-gui-matlab command (see documentation on configuration file):
>> circus-gui-matlab mydata.extension -e suffix